What is HTML?
Page Bookmarks
HTML Elements
To create HTML documents we use multiple "HTML elements". HTML has multiple pre-defined kind of elements defined by tags. In the next picture we show an example of element, created with tag "div" that is used as a container that holds a short text.

HTML Element Anatomy
This is the big secret that you need to know to understand HTML more easily: HTML is a domain specific XML with predetermined elements and attributes designed to describe an Internet document. Therefore HTML is sometimes called XHTML.
Example
Let's read this HTML example and then we comment below the content and the syntax.
<HTML>
<!-- this is a comment -->
<HEAD>
<TITLE>Your Title Here</TITLE>
</HEAD>
<BODY>
<CENTER><IMG SRC="clouds.jpg" ALIGN="BOTTOM"></CENTER>
<HR>
<P>This is a link to our website</P>
<A href="https://sagecode.pro">SageCode Home Link</A>
<H1>This is a Header</H1>
<H2>This is a Medium Header</H2>
<P> This is a regular paragraph.</P>
<P><B>This is a bold paragraph!</B></P>
<BR>
<P><I>This is an italic sentence.</I></P>
<HR>
</BODY>
</HTML>Note:In this example we have used some of the HTML "elements" called also "tags". You can observe the names of the HTML elements are capitalized in this example. However HTML is not case sensitive. Modern HTML is using lowercase for element names and attribute names. This document contains one image, one link and several lines of text.
Homework: Open example with codepen.io: HTML First example
As you can see HTML is clattered with symbols that you may not comprehend and can be difficult to read, especially when is not aligned properly by a human hand. We can use some tricks to make HTML more readable. For example we can split a paragraph in several lines.
The browser will eliminate the line breaks into a paragraph. Also the empty spaces are eliminated by the browser and reduced to one. So we can use indentation in the HTML code and this do not have any negative effect on the aspect of HTML document.
Used Elements:
In the example above we have used these elements:
- <HTML> is the root element,
- <HEAD> is the html header section,
- <BODY> is the main content of the page,
- <BR> is a line break, also known as new line,
- <HR> is used to insert a horizontal line ,
- <IMG> is used to insert a image,
- <a href="/html/"> is used to create a hyperlink,
- <H1>, <H2>, <H3> are headers on different levels,
- <P> is paragraph of text, it can span multiple lines of text.
Types of elements
There are 3 kind of elements in HTML:
- empty elements,
- block elements,
- in-line elements.
Empty elements
These are the most simple elements possible. They have only start tag and no end tag. We use these elements to produce an effect that will be otherwise difficult to represent in HTML.
- <br> line break,
- <hr> horizontal line separator,
- <img> insert image in HTML page.
Notes:
- Notation for an empty element is using self-closing symbol: />, In this case you do not have to use the closing tag element.
- You can close tag elements even if do not have any content like this: <img src=""></img>.
Block elements
The <HTML> is the root element of HTML files. This has two children: <HEAD> and <BODY>. The spaces used for indentation are ignored. Actually all the spaces are ignored by a browser when rendering the HTML files. Multiple spaces between words are reduced to one space.
Block elements can display a text on one or more lines. The block element can't apply to a section of text. A block elements can have multiple other elements inside. The most common block elements are: paragraph <p> and division <div>.
A division block <div> is very useful to organize your web pages in nested blocks, like panels. Each <div> block can contain multiple other <div> blocks or paragraphs, html tables, input forms or images.
In line elements
In-line tags can apply to a small portion of text. This elements are usually not contain other tags only a small chunk of text. In the example above we have used several inline tags: <B> is bold text and <I> is italic text. In-line tags can be combined (nested) and can have a cumulative effect if apply to the same text fragment.
WYSIWYG Editors
To improve productivity one can use a WYSIWYG tool to create HTML. This can be embedded editor into a website that is able to edit HTML. For example a blogger have access to buttons for text formatting. WordPress has an embedded editor that is created in JavaScript to aid HTML text authors create content much faster.
Only programmers are using plain text editors to create HTML fragments. If you use WYSIWYG editor like I do, you can learn HTML by looking at the source code. Sometimes you must fix syntax using text mode. I usually put class and other style attribute for <div> or <table> in text mode.
HTML Entities
Some characters can't be included inside HTML tags. For example: the characters < and > are the markups in the XML language. So these characters are found by the HTML parser (that is the browser) and interpreted as tag markers. If used in a text content can confuse the parser. Therefore you must replace < with: < and > with: > These special characters are called "HTML Entities".
That is, special symbols in XML and in HTML are represented by a code starting with symbol & and ending with ;. We can also use a number that is a special code for the symbol we wish to represent by using notation &#num; Here are other special characters that can be encoded in HTML text content:
| Symbol | Description | Code | Number |
|---|---|---|---|
| _ | non-breaking space | |   |
| < | less than | < | < |
| > | greater than | > | > |
| & | ampersand | & | & |
| " | double quotation mark | " | " |
| ' | single quotation mark | ' | ' |
| ¢ | cent | ¢ | ¢ |
| £ | pound | £ | £ |
| ¥ | yen | ¥ | ¥ |
| € | euro | € | € |
| © | copyright | © | © |
| ® | registered trademark | ® | ® |
Hacking HTML
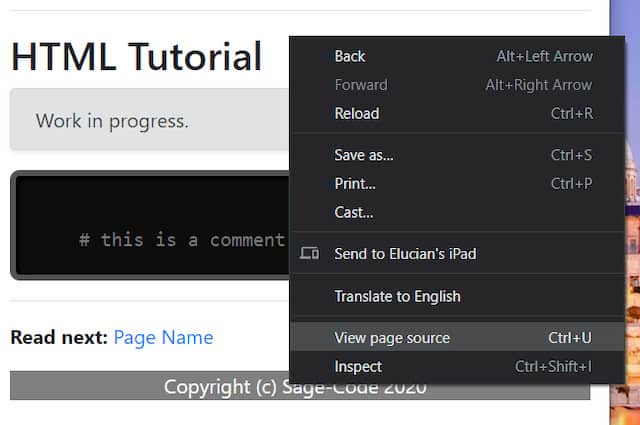
You can visualize HTML for any web page in your browser. This is not a good method to learn HTML. However, sometimes when you make a website you may need to visualize the HTML. For this you use right click over a web page and open a context menu. There is the option "View page source".
Homework:
Click the image below to ope the template page that I use for making this tutorial. Then, use right-click and "View page source" to see the HTML code. Notice if you right-click over an image, the menu is different. In this case you can use "inspect" option to open the HTML code.
Read next: HTML Tags